Digitálne pramene – národný projekt zberu a archivácie v roku 1
Kľúčové slová: archivácia webu, zber webu, webová analytika, WARC, e-Born pramene, digitálne kurátorstvo, ISSN
Summary: In 2015 the University Library in Bratislava put in the practice the national project Digital Resources – Webharvesting and E-Born Content Archiving. The project was running in the framework of the Operational Program Informatisation of Society. Its ambition was to establish a technical, application and management infrastructure for systematical harvesting and long term preservation of web pages and e-Born resources. The implementation is based on open source software modules (Heritrix, OpenWayback, Invenio). The systems management is optimized for parallel webharvesting. This article presents the experiences and results of the operation of IS Digital Resources in 2016. It describes the workflow of webharvesting and acquisition of e-Born resources and discusses some methodological and practical problems in dealing with e-Born serials. The article brings the analytical and statistical overview of harvests realised in 2016 with a special highlight on the complex harvest of the national .sk domain.
Keywords: web archiving, webharvesting, web analytics, WARC, e-Born resources, digital curation, ISSN
Ing. Alojz Androvič, PhD., Bc. Andrej Bizík, Ing. Peter Hausleitner, PhDr. Beáta Katrincová, Mgr. Iveta Lacková, PhDr. Jana Matúšková / Univerzitná knižnica v Bratislave (The University Library in Bratislava), Michalská 1, 814 17 Bratislava
Úvod
Digitálne pramene, bezhranične rastúci pôvodný a odvodený digitálny obsah, sú pre spoločnosť aktuálnou výzvou. Pre knižnice to platí už najmenej dve desaťročia. Svedčia o tom experimenty s repozitárom Greenstone, prvé (domáce) pokusy o zavedenie elektronického povinného výtlačku z deväťdesiatych rokov minulého storočia, ako aj úspešné projekty, akým sa stal český Webarchiv (webarchiv.cz) na prelome tisícročia. V rokoch 2004–2005 iniciovala Národní knihovna ČR európsky projekt Web Cultural Heritage, do ktorého prizvala aj Univerzitnú knižnicu v Bratislave (UKB). Aj vďaka tomu nebola problematika archivácie digitálnych prameňov u nás cudzia a stala sa témou Operačného programu informatizácie spoločnosti, ktorý sa začal formovať už v roku 2007 a realizovať s podporou finančných prostriedkov z fondov EÚ od roku 2011. V rokoch 2012–2014 realizovala UKB národný projekt Centrálny dátový archív (CDA) a v apríli 2015 bola poverená riešením národného projektu Digitálne pramene – webharvesting a archivácia e-Born obsahu. Projekt bol k 31. 12. 2015 ukončený a 1. januára 2016 bola zahájená rutinná prevádzka informačného systému Digitálne pramene (DIP). Rok 2016 je teda prvou etapou záväznej päťročnej udržateľnosti projektu.
Zadanie a návrh informačného systému DIP
Cieľom projektu DIP bolo vybudovanie odpovedajúcej technickej, aplikačnej a organizačnej infraštruktúry pre systematický zber a dlhodobú archiváciu slovacikálnych webových publikácií a pôvodného elektronického obsahu. Oficiálny rámec zadania určil len základné formálne ukazovatele projektu: počet informačných a dokumentačných databáz, počet nových technických zariadení, počet nových elektronických služieb on-line a napokon počet novovytvorených pracovných miest obsadených ženami a mužmi. Samotné zadanie predstavovalo komplexný súbor funkčných a nefunkčných požiadaviek na architektúru, prieskum WWW, akvizíciu DIP, záber, kvalitu a kompletnosť, vykazovanie, katalóg, sprístupňovanie, dlhodobú archiváciu a správu systému. Požadovaná funkcionalita sa odrazila v architektúre systému (obr. 1), ktorú tvoria autonómne, navzájom prepojené funkčné bloky: verejný portál, interný portál, zberový blok (cluster) a repozitár. Dlhodobá archivácia sa rieši napojením na systém CDA.
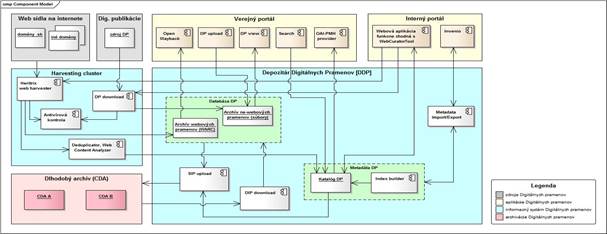
Obr. 1 Funkčná schéma IS DIP
Implementácia IS DIP sa opiera o existujúce, v praxi overené softvérové nástroje. Preferovali sa najmä stabilné a v komunite udržiavané Open Source komponenty. Základom sú operačné systémy na báze Linux Red Hat. Ako relačná báza sa použil objektovo relačný DB systém PostgresSQL. Operačné prostredie dotvárajú komponenty Apache HTTP server, Apache Tomcat a Apache Solr. Systém na zber webového obsahu je postavený na aplikácii Heritrix, ktorá bola vyvinutá spoločnosťou Internet Archive. Na sprístupňovanie sa využíva softvérový nástroj OpenWayback, vyvinutý na základe iniciatívy konzorcia IIPC. Ako katalóg e-Born prameňov sa využíva softvér digitálnej knižnice Invenio z dielne CERN.
Technické riešenie
Technické riešenie informačného systému DIP (obr. 2) je optimalizované na paralelný zber, spracovanie a indexáciu webového obsahu. Využíva výkonnú virtualizačnú platformu, ktorá je založená na 21 fyzických serveroch. Na nej sa podľa rozsahu a intenzity zberu aktivuje potrebná kapacita virtuálnych serverov a počet zberových robotov. Každý robot realizuje spracovanie jednej konkrétnej stránky alebo podstránky pričom postupne vykonáva predpísané operácie. Obsahuje všetky softvérové komponenty na zber a transformáciu webovej stránky na archívny balík vo formáte WARC. Správu robotov zabezpečuje riadiaci server. Roboty využívajú zdieľaný diskový priestor.
Tri fyzické servery slúžia na riadenie aplikačných databáz, ukladanie zozbieraného obsahu a príslušných metaúdajov vo forme archívnych balíkov. Tieto servery nie sú vzhľadom na predpoklad intenzívneho využitia diskového úložiska virtualizované. Pre potreby spracovania, indexácie a archivácie je informačný systém DIP vybavený diskovým podsystémom s kapacitou 800 TB, čo výhľadovo spĺňa požiadavky na pracovný a úložný priestor vrátane potrebnej redundancie.
Obr. 2 Technická schéma DIP
Diskové polia slúžia ako primárne blokové dátové úložiská. Sú pripojené cez vysokorýchlostnú internú sieť. Konektivita DIP navonok je zabezpečená prostredníctvom akademickej siete SANET (1 Gbit). Interná sieť je chránená a oddelená od verejne prístupnej siete.
Podporná infraštruktúra je fyzicky oddelená od modulov spracovania. Systémové aktíva (operačné prostredia, aplikácie a ich konfigurácie) sa zálohujú na páskovej knižnici. Priebežné výkonové parametre a prevádzkové stavy komponentov infraštruktúry sa monitorujú systémom Tivoli. Informačný systém DIP je pod stálym dozorom zmluvného dodávateľa servisných služieb.
Riadenie procesov informačného systému DIP
Prevádzku, správu a rozvoj informačného systému DIP zabezpečuje v súčasnosti štvorčlenný tím v rámci samostatného oddelenia Depozit digitálnych prameňov (DDP). Informačné procesy DIP zahŕňajú komplexné pracovné postupy zamerané na široké spektrum prameňov od webových stránok, cez rôzne typy e-Born seriálov (elektronické časopisy, aktualizované webové stránky) až po elektronické monografie. Podľa rôznorodej povahy archivovaných prameňov je zodpovednosť rozdelená medzi kurátorov WWW a kurátora e-Born prameňov.
Ťažiskom práce kurátora WWW je webová žatva, t.j. proces automatického stiahnutia obsahu webových stránok pre účely ich dlhodobej ochrany a archivácie. Z hľadiska praxe rozlišujeme tematický, výberový a celoplošný zber. Pri tematickom zbere sa webové stránky vyberajú podľa témy a aktuálneho diania. Zber sa realizuje podľa potreby, väčšinou opakovane. Výberový zber sa realizuje podľa zoznamu inštitúcií, s ktorými sú podpísané zmluvy o spolupráci. Opakuje sa spravidla 4x ročne. Posledným typom zberu je celoplošný zber. Jedná sa o zber všetkých dostupných webových sídiel v stanovenom rozsahu a hĺbke, podľa prijatej politiky zberu. Zber sa prednostne zameriava na WWW pramene z domény .sk. Okrem národnej domény sa zbierajú aj WWW pramene s príponami .com, .org, .net, .eu, ak spĺňajú kritérium slovacikálneho charakteru. Tieto treba doplniť do katalógu DIP manuálne. Celoplošný zber sa uskutočňuje najmenej raz ročne. Kurátor WWW prameňov konkretizuje v súlade s politikou zberu tému a časový harmonogram zberov. Zhromažďuje ciele podľa danej témy. Priebežne oslovuje oprávnené inštitúcie a v prípade záujmu s nimi uzatvára Zmluvu o poskytovaní elektronických online prameňov.
Pramene pre archiváciu sa vyberajú podľa kritérií uvedených v politike zberu. Pramene sa navrhujú dvomi spôsobmi:
a) prameň navrhne kurátor webového archívu,
b) prameň navrhne poskytovateľ alebo používateľ prostredníctvom elektronického formulára na webovej stránke DIP [www.webdepozit.sk] .
Pred schválením webového prameňa pre archiváciu vykoná kurátor viacstupňovú kontrolu a v testovacom prostredí IS DIP realizuje testovacie zbery. Vďaka tomu sa optimalizujú nastavenia konfigurácie zberov. Nasleduje oslovenie poskytovateľa s návrhom zmluvy.
Tematický, výberový či celoplošný zber vyžadujú rôzne nastavenia Heritrixu. Trojica parametrov, na ktoré sa pri žatve prihliada, sú obmedzenia času, maximálneho počtu zbieraných objektov a objemu dát na doménu. Ako príklad môžeme uviesť použité nastavenie výberového zberu spolupracujúcich inštitúcií (tabuľka 1). Tieto parametre Heritrixu sa podľa požiadaviek praxe môžu upravovať a sú nastaviteľné priamo z prostredia interného portálu DIP.
|
ZML |
||
|
Limity |
na objekt |
1 500 000 |
|
na objem |
2GB |
|
|
na čas |
72 h |
|
|
Frekvencia zberu |
4 x ročne |
|
Tabuľka 1 Základné nastavenia zmluvného zberu
Základom riadenia zberu je práca s katalógom domén. Katalóg domén je súčasťou interného portálu DIP. Slúži na výber cieľovej sady – zoznamu URL adries pri každom zbere. Katalóg domén sa cyklicky aktualizuje na základe automatizovaného prieskumu národného registra domén SK-NIC. Do katalógových záznamov sa vkladajú údaje o registrantovi a držiteľovi domény a metaúdaje extrahované zo záhlavia úvodnej stránky (kľúčové slová, popis). V internom portáli má kurátor naviac možnosť priradiť jednotlivým doménam kategóriu konspektu, podľa ktorej sú domény na verejnom vyhľadávacom portáli DIP vyhľadateľné.
Kurátor WWW prameňov sa pri svojej práci stretáva s rôznorodými webovými stránkami, ktoré fungujú na rôznych technických riešeniach. Tomu sa priebežne prispôsobuje nastavenie zberu. Ako príklad možno uviesť správanie niektorých domén – kde správne zozbieranie raz funguje s univerzálnou predponou „www“, no inokedy to tak nie je. Doména 2. úrovne môže mať bez „www“ úplne iný obsah. Pre stránky, ktoré si inštitúcie neželajú zbierať, sa prostredníctvom regulárnych výrazov nastavujú výnimky (crawler traps). Osobitné nastavenie si vyžaduje aj korektné zobrazovanie niektorých typov dynamických stránok. Nastaveniami Heritrixu sa určujú typy súborov a sekcie stránok, ktoré sa zbierať nemajú (podľa politiky zberu alebo podmienok v zmluve). To znamená, že nastavenia Heritrixu majú dopad na zozbieraný počet objektov a riadenie výnimiek zberu. Chybné nastavenie konfiguračného súboru Heritrix môže spôsobiť nečakané problémy.
Osobitne sledovaným prvkom pri zbere WWW je deklarácia robots.txt, ktorú informačný systém DIP všeobecne rešpektuje. To spravidla spôsobuje, že zobrazenie stránok v archíve sa nezhoduje so zobrazením reálnej stránky (chýbajú napríklad obrázky). Všetky výsledky zberov je možné zobraziť v bádateľni Univerzitnej knižnice v Bratislave lokálne, okrem tých, ktoré majú zobrazenie zakázané. Obsah zberov pre zmluvné domény a domény s verejnou licenciou je dostupný verejnosti online.
E-Born pramene
E-Born archív a e-Born katalóg je prípravou na prijímanie povinného výtlačku on-line publikácií. Avšak až do prijatia odpovedajúceho zákona treba uzatvárať zmluvy s vydavateľmi, aby bolo možné uchovávať a sprístupňovať e-Born on-line publikácie. Prednostne sa archivujú tituly e-Born časopisov, ktoré vychádzajú len v on-line verzii, keďže platný zákon o povinných výtlačkoch neukladá vydavateľom povinnosť odvádzať uvedené tituly. Povinné výtlačky sa v súčasnosti odovzdávajú v zmysle Zákona o povinných výtlačkoch z tlačených periodických publikácií a publikácií na CD-ROM. Avšak produkcia publikácií v on-line forme je čoraz väčšia a hoci sa uvedené publikácie už dlhšiu dobu registrujú v systéme ISSN, doposiaľ sa nearchivovali. Aktuálne je v slovenskej databáze ISSN zaevidovaných 969 titulov s prideleným ISSN, z toho vychádzajúcich 755, z toho 434 originálov (údaj z 3. 11. 2016). Archivujú sa výlučne identifikované e-Born pramene, t.j. pramene spĺňajúce kritériá ISSN. ISSN sa prideľuje publikáciám vo forme čísel alebo aktualizovaných webových stránok, ktoré majú jednoznačný názov, obsahujú plnotextové články a vydavateľské údaje. Vylúčené z registrácie ISSN sú: domovské stránky inštitúcií a organizácií, webové stránky súkromných osôb vrátane blogov, stránky s počítačovými hrami, reklamné a propagačné webové stránky, katalógy produktov alebo akcií, stránky miestneho významu.
Archivácia e-Born publikácií zahŕňa registráciu vydavateľa, vklad titulov e-Born publikácií – seriálov a monografií a vklad jednotlivých čísel. Vydavateľa v súčasnosti registruje kurátor, neskôr sa bude môcť cez verejný portál zaregistrovať aj sám. V archíve e-Born seriálov sa môžu ukladať len seriálové publikácie s prideleným ISSN, v archíve e-Born monografií iba on-line monografie s prideleným ISBN. Pri vklade údajov o titule sa uvádzajú základné údaje, ktoré kurátor obohacuje o údaje zo záznamu z e-Born katalógu. Záznamy sa do e-Born katalógu získavajú importovaním záznamov on-line časopisov z národnej databázy ISSN.
V blízkej budúcnosti plánuje Národná agentúra ISSN (ďalej len NA ISSN) rozšíriť žiadosť o pridelenie ISSN o údaj o záujme vydavateľa o archiváciu e-Born publikácie. Tiež sa pripravuje užšie prepojenie medzi archívom DIP a registrom ISSN uvedením informácie o archivácii v zázname titulu. Zaindexovaním tohto údaja vo voľne prístupnej národnej databáze bude možné vyhľadať archivované tituly aj cez národnú databázu ISSN (www.issn.sk). V záznamoch ISSN u skončených titulov sa plánuje uvádzať linky do archívu DIP.
Pri získavaní vhodných e-Born prameňov spolupracuje e-Born kurátor s Národnou agentúrou ISSN. Agentúra poskytuje tituly z databázy ISSN a kurátor z nich vyberá tituly berúc do úvahy nasledovné kritériá: titul zaradený do archívu má mať publikovaný minimálne jeden ročník, v prípade, že je publikovaný v číslach, t.j. aspoň dve čísla, napriek tomu, že na pridelenie ISSN stačí publikovať jedno kompletné číslo. Kurátor použije údaje zo záznamu na vstup do titulu (856 URL adresa), v prípade nefunkčnosti URL adresy komunikuje s pracovníkmi agentúry. Zo záznamu ISSN (formát MARC 21) je možné tiež zistiť, či je titul zverejnený pod verejnou licenciou Creative Commons. Informácie o časopisoch v režime otvoreného prístupu sa nachádzajú v poli 856. Vydavateľov titulov, ktoré nie sú zverejnené pod verejnou licenciou, oslovuje kurátor s ponukou na ich archiváciu a komunikuje s nimi ohľadom uzatvorenia licenčnej zmluvy (vydavatelia titulov zverejnených pod verejnou licenciou Creative Commons sú informovaní o zaradení medzi archivované publikácie, ktoré sa sprístupňujú na základe uvedenej licencie). V prípade pozitívneho záujmu o archiváciu zisťuje kurátor zo záznamu ISSN typ e-Born prameňa, či sa jedná o seriál (periodical), t.j. titul publikovaný v číslach, alebo o aktualizovanú webovú stránku. V testovacom prostredí intranetovej aplikácie Digitálne pramene pokračuje kurátor testovacou fázou a realizuje testovacie zbery. Prax potvrdila, že testovaciu fázu je veľmi dôležité realizovať ešte pred podpísaním samotnej zmluvy. Testy zberu sa vykonávali na rôznych e-Born seriáloch a monografiách s cieľom zistiť optimálny spôsob uloženia publikácií do archívu.
Elektronické monografie sa väčšinou ukladajú do archívu ako súbory vo formáte .pdf alebo ePub, pre e-Born seriály je situácia zložitejšia. V prípade rozsiahlejších ročníkov a zložito štruktúrovaných titulov je nutná komunikácia a aktívna súčinnosť vydavateľov najmä pri ukladaní celých ročníkov do archívu.
U e-Born seriálov rozoznávame podľa spôsobu publikovania tri hlavné typy: 1. celé čísla v .pdf, 2. jednotlivé čísla pozostávajúce z článkov v .pdf, 3. tituly publikované v podobe aktualizovaných webových stránok, t.j. články sa dopĺňajú postupne, v určitých intervaloch. Pri testovaní viacerých titulov sa zistilo, že môžu nastať aj kombinácie uvedených typov, resp. zmena jedného typu na iný. V rámci jednotlivých typov môžu mať tituly rozličný spôsob usporiadania čísel, resp. článkov. V archíve DIP je uložených momentálne 12 titulov e-Born publikácií, na ktoré sa uzatvorili zmluvy, z toho 6 titulov typu .pdf čísel, 2 tituly typu .pdf články, 4 tituly typu aktualizovaná webová stránka.
Najjednoduchšie archivovateľné sú seriály, ktoré majú celé čísla v .pdf formáte. Existujú dva spôsoby ich uloženia do archívu: je ich možné zozbierať alebo jednotlivé čísla nahrať vo formáte .pdf. Ako príklad možno uviesť internetový časopis Dejiny (ISSN 1337-0707), ročníky 2006–2016. Najjednoduchším spôsobom archivácie tohto titulu by bol zber starších ročníkov a ukladanie jednotlivých čísel aktuálneho ročníka v .pdf formáte. Testovaním sa však zistilo, že automatický zber starších ročníkov nie je možný z dvoch dôvodov:
1) pri zberoch by sa v katalógu domén kumulovalo veľké množstvo URL adries,
2) nebol by umožnený prístup k jednotlivým číslam v archíve.
Obr. 3 Pohľad na webovú stránku internetového časopisu Dejiny
Druhý typ, pri ktorom jednotlivé čísla tvoria samostatné články v .pdf, prináša tituly s rozličným usporiadaním článkov. Príkladom tohto typu je titul Journal of Microbiology, Biotechnology and Food Sciences (ISSN 1338-5178), kde každý ročník má vlastnú URL, na ktorej sú všetky čísla ročníka. Celkovo je v 6 ročníkoch okolo 500 článkov v .pdf formáte, ktoré si vyžadujú manuálny vklad. Do archívu sa sťahujú čísla počnúc podpísaním zmluvy, t. j. rok 2016 – 6 čísel, 125 článkov.
Seriály vo formáte aktualizovanej webovej stránky, na ktoré máme podpísané licenčné zmluvy (Feel Art – ISSN1338-421X, Prohuman – ISSN 1338-1415, Projustice – ISSN 1339-1038, Promanager – ISSN 1338-8584), sa archivujú automatickým zberom stránok. Zbery majú nastavené presné limity (tabuľka 2) a konfiguračný súbor s ignorovaním robotov. Nastavenie limitov sa realizuje v spolupráci s kurátorom webových prameňov.
|
Limity pre zber e-Born |
||
|
Limity |
na objekt |
1000000 |
|
na objem |
900MB |
|
|
na čas |
48 h |
|
|
Frekvencia zberu |
podľa aktualizácie stránky, čo vyžaduje pravidelnú kontrolu obsahu kurátorom e-Born |
|
Tabuľka 2 Základné nastavenia pre zber e-Born
Archivovaný obsah je možné vyhľadať a zobraziť na webovej stránke www.webdepozit.sk.
Pokiaľ ide o monografie, testovalo sa niekoľko publikácií, napr. Život a dielo Jána Amosa Komenského (ISBN978-80-555-0161-1). Uvedený titul je publikovaný vo viacerých .pdf súboroch (8). Ďalším titulom bola publikácia Pavol Lacko: Jeden za všetkych, nikto za jedného (ISBN 978-80-89-790-06-7), kde je celý dokument v jednom .pdf súbore.
Uzatváranie zmlúv s poskytovateľmi WWW
Vplyv na konkrétne výstupy zberov pre verejnosť majú nastavenia zberov a zobrazovania obsahu domén, ktoré sa nastavujú v intraportáli. Implicitne sa považuje zbieranie všetkých domén z katalógu DIP za povolené, no s rešpektovaním už spomínaných robots.txt. Pri kontakte s vlastníkom WWW stránky (spravidla po oslovení) sa upresňujú limity a nastavenia sprístupnenia zozbieranej domény (verejný prístup, prístup iba v knižnici, zakázaný prístup).
Zmluva o poskytovaní elektronických on-line prameňov sa pripravila v spolupráci s právnikom, odborníkom na autorské právo. Uzatvorenie zmluvy prebieha výlučne na báze dobrovoľnosti zo strany poskytovateľa (vydavateľa), ktorý sám rozhoduje o tom, čo umožní zbierať (čiže archivovať) resp. sprístupniť a v akom režime.
Sprístupňovanie archivovaných elektronických prameňov je v súlade s platným autorským zákonom nutné riešiť podpísaním licenčnej zmluvy s vydavateľmi (resp. poskytovateľmi). V prípade elektronických prameňov označených verejnými licenciami Creative Commons zmluvy uzatvárať netreba.
V súčasnosti sú možné tri typy prístupu k prameňom v archíve:
a) voľný prístup (neobmedzený, odkiaľkoľvek),
b) lokálny (obmedzený na vybrané počítače v priestoroch Univerzitnej knižnice v Bratislave),
c) bez prístupu (prístup zakázaný).
Od 6. novembra 2015 do 31. októbra 2016 oslovili kurátori Depozitu digitálnych prameňov 445 inštitúcií, z toho 38 vydavateľov e-Born seriálov. Na prvé oslovenie zareagovalo (či už kladne, ale aj záporne) 108 inštitúcií (vydavateľov), podpísalo sa 71 zmlúv. 47 inštitúcií bolo oslovených druhýkrát, podarilo sa uzatvoriť 22 zmlúv. Celkový počet uzatvorených zmlúv je 94. Nakoľko na jednej zmluve môže byť uvedených niekoľko URL adries, resp. e-Born prameňov, celkový počet zmluvných URL adries je 123. Z tohto počtu je 111 webových stránok a 12 sú e-Born tituly (elektronické seriály, z toho 4 seriály typu aktualizovanej webovej stránky).
Pri uzatváraní zmlúv sa opakovane vyskytovali najčastejšie tieto problémy:
- nevyplnená hlavička (kontaktné údaje poskytovateľa), prípadne chybná adresa alebo PSČ,
- chýbajúci podpis,
- nevyplnená, prípadne chybne vyplnená príloha (URL, typ prístupu),
- zaslaný iba 1 exemplár zmluvy (namiesto dvoch).
V mnohých prípadoch bolo potrebné poskytnúť bližšie a doplňujúce informácie k zmluve, vysvetliť definície niektorých termínov a bodov zmluvy. Konzultácie sa najčastejšie poskytovali mailom, telefonicky, v jednom prípade aj osobne. Vo viacerých prípadoch požadoval poskytovateľ úpravy alebo doplnenie zmluvy, čo aktuálne nie je možné. Z oslovených inštitúcií nemá v súčasnosti záujem o zapojenie sa do projektu 6 inštitúcií, dve si archiváciu vyslovene neželajú. Tieto inštitúcie sú zo zberu vylúčené.
Prehľad zrealizovaných zberov v roku 2016
Prvý tematický zber bol venovaný parlamentným voľbám, ktoré sa konali 5. marca 2016. V januári sa začalo s oslovovaním politických subjektov, ich kandidátov, prieskumných agentúr a politologických inštitútov. Kladnú odpoveď a zmluvný súhlas s archiváciou webových stránok vyjadrilo 9 oslovených (12 domén). Webharvesting Parlamentné voľby 2016 bol spúšťaný v týždenných intervaloch od januára do apríla, zbierali sa nielen zmluvne podchytené URL, ale aj širší okruh súvisiacich webových stránok (s rešpektovaním politiky robots.txt a bez sprístupnenia verejnosti). Celkovo sa v katalógu Webdepozitu z tejto tematickej kampane nachádza 227 URL s objemom dát prevyšujúcim 330 GB.
Séria desiatich tematických zberov pod spoločným názvom Kultúrny profil Slovenska prebehla od júna do augusta 2016. Zaradili sa sem webové stránky slovenských knižníc, galérií, múzeí a najznámejších folklórnych festivalov. Zozbieraný objem dosahuje 60 GB.
Jednou zo súčasných udalostí s medzinárodným významom je predsedníctvo Slovenskej republiky v Rade Európskej únie (SKEU 2016). Webové stránky týkajúce sa predsedníctva sa zbierajú od jeho začiatku 1. 7. 2016 v dvojtýždňových intervaloch až do konca roka 2016.
V júli 2016 sa archivovala úspešná účasť Petra Sagana na Tour de France, zachytená na slovenských webových stránkach. V auguste a v septembri prebiehala kampaň Rio 2016, do ktorej boli zahrnuté stránky Slovenského olympijského výboru a Slovenského paralympijského výboru.
Počas tohto roka sa realizovali dve výberové kampane zmluvných inštitúcií (údaj k 30. novembru 2016). Prvá kampaň prebiehala vo viacerých etapách od mája 2016 až do augusta 2016. V prvej fáze sa zbierali domény zmluvných inštitúcií so zmluvami uzavretými v roku 2105, v druhej etape podľa zmlúv z roku 2016. V poslednej etape boli zbierané weby zmluvných inštitúcií z rokov 2015 aj 2016, ktorých nastavenia sa museli zvlášť otestovať (výnimky Heritrixu, zbieranie s predponou „www“ a bez nej).
Druhý výberový zber zmluvných inštitúcií prebiehal na prelome septembra a októbra 2016. Tento zber bol prerušený z dôvodu zacyklenia pri príprave jednej domény, čo sa opravilo pri nasledovnom zbere. 95 domén tohto zmluvného zberu dosiahlo celkový objem zozbieraných dát prevyšujúci 87 GB.
Celoplošný zber domény .sk
Slovenská doména .sk vyhradená pre slovenský internet vznikla v roku 1993 a jej správou je poverená spoločnosť SK-NIC. SK-NIC eviduje k 17. 10. 2016 celkovo 338 076 funkčných domén (graf 1). Počet domén má rastúci charakter.
Graf 1 Počet domén .sk
Slovenský webový archív Digitálnych prameňov eviduje v katalógu webových stránok 360 639 domén rôznych úrovní, ktoré sa podľa potreby upravujú a dopĺňajú. Podľa dotazu na doménu je 66 329 domén nedostupných a 4 691 má neznámy stav domény (stav k 17. 10. 2016).
V októbri 2016 prebehol celoplošný (celodoménový, komplexný) zber. Pre tento zber sa určili maximálne limity na doménu 5 000 objektov, 1 hodina a 200 MB. Úspešne sa podarilo zozbierať 278 610 domén slovacikálneho charakteru v objeme vyše 10 TB (tabuľka 3). Celoplošný zber v danom nastavení trval celkom 4 dni (cca 96 hodín).
|
MB |
GB |
TB |
B |
|
|
Nekomprimovaná veľkosť |
10963839 |
10706.87 |
10.456 |
11496418631813 |
|
Komprimovaná veľkosť |
7181265 |
7012.95 |
6.849 |
7530102562089 |
|
Úspešných URL z katalógu DDP |
278610 |
|||
|
Neúspešných URL z katalógu DDP |
16253 |
Spustenie |
8:11:00 |
|
|
Zrušených pre zber / vynechaných z katalógu DDP |
65765 |
7.10.2016 |
||
|
Počet zozbieraných úspešných url (domény aj mimo katalógu DDP) |
278642 |
Ukončenie |
8:37:00 |
|
|
Počet WARC |
278663 |
11.10.2016 |
Tabuľka 3 Základné údaje o celodoménovom zbere 2016
Zo všetkých úspešne zozbieraných URL bola priemerná veľkosť zozbieraného obsahu na jednu doménu 39,35 MB (graf 2). Na limite počtu objektov skončilo 8872 stránok. Veľkosť do 1 kB zodpovedá hlavne doménam, ktoré existujú, no na stránke sa nenachádza žiaden obsah. Do 1 MB sú zväčša stránky obmedzené pomocou nastavení v súbore robots.txt, čiže archivovaný obsah je súbor s informáciou DNS servera a súbor robots.txt zakazujúci zber. O týchto obmedzujúcich nastaveniach častokrát vlastníci stránok nevedia, keďže ich stiahli napríklad spolu so šablónou. Pri uzatváraní zmlúv sa tento súbor konzultuje, aby bolo možné vykonať archiváciu dôveryhodne a úplne.
Graf 2 Rozdelenie domén podľa veľkosti v MB
Podľa predpokladov sa najviac objektov vyzbieralo s html obsahom, ktorý prevláda nad ostatnými s počtom objektov 106 milióna. Jedna stránka obsahuje priemerne 380 html objektov. Mnohé stránky obsahujú články a odkazy, ktoré majú osobitné adresy. Na druhom mieste sa v počte objektov umiestnili obrázkové formáty img, v ktorých dominoval najpoužívanejší formát JPEG s počtom 76 milióna objektov, hneď za ním nasledoval formát png s počtom 14 mil. objektov. Ostatné obrázkové formáty ako bmp (3 mil.) , icon (754 tis.) a ďalšie sa veľmi nevyužívali, preto boli v menších počtoch. Na jednu doménu pripadá priemerne 273 img objektov. K dizajnu stránky patria neodlúčiteľne aj kaskádové štýly css, čo potvrdil ich počet 3,9 milióna, pričom ich priemer je 13 na doménu. Ďalší populárny formát je javascript s počtom 3,5 milióna. Medzi iné najviac vyskytujúce sa formáty (graf 3 vpravo) patria rtf, zip, pdf, xml, dns, json, neznáme a ostatné, kde medzi ostatné sa radia ďalšie zriedkavo sa vyskytujúce alebo aj chybne zadané, napríklad htl, csss, jpe a pod.
Graf 3 Počet zozbieraných objektov v tisícoch (podľa formátov)
Nielen v počte objektov, ale aj veľkosťou dominujú img a html formáty. Obrázkové img formáty majú najväčšiu veľkosť 4,97 TB, hneď za nimi sú html stránky – 3,23 TB, s priemerom 32 KB na jeden objekt. Na treťom mieste sa umiestnili formáty pdf s veľkosťou 1,33 TB; ich priemerná veľkosť bola 1,1 MB. Na základe štatistík je možné predpokladať, že veľkosť formátu pdf by rástla aj pri ich menšom počte, ak by sa zber uskutočnil bez obmedzení. Rovnako by rástla aj veľkosť formátov img a html, ktorá je ale úmerná počtu objektov zo zberu. Zvyšnú časť zaberajú hlavne textové typy, no pri zbere multimediálnych alebo zip formátov vo väčšom množstve by sa do popredia zaradili aj niektoré ďalšie, ako napríklad mp4, avi a podobne.
Graf 4 Zozbieraný objem podľa formátov v TB
Štatistika IS DIP
IS DIP využíva na archiváciu webového obsahu súbory vo formáte WARC. Pre každú webovú URL adresu zo zberu sa vytvoria vlastné súbory WARC. Jeden WARC má maximálnu veľkosť 2 GB a pri prekročení limitu sa pre danú doménu vytvorí viacero súborov WARC. Archivácia pracovných súborov sa komprimuje do súboru ZIP. Vznikne finálny súbor WARC s príponou súboru „warc.gz“.
Štatistické údaje o počte súborov WARC v IS DIP sa sledujú od januára 2016. K 3. 10. 2016 obsahoval archív Webdepozitu 1726 súborov Warc a po októbrovom celoplošnom zbere to už bolo viac ako 280000 súborov WARC (graf 5).
Graf 5 Počet súborov WARC v r. 2016
Priemerná veľkosť jedného nekomprimovaného súboru WARC je približne 348,5 MB. Ich celková komprimovaná veľkosť je 304 GB a nekomprimovaná 587 GB. Komprimácia teda ušetrí približne 48 % miesta z celkovej veľkosti súborov WARC.
Graf 6 Zozbieraný objem v GB za mesiace 2016
Graf 7 Počet domén prvej úrovne v katalógu DIP – november 2016
Graf 8 Zaplnené miesto na diskoch DIP – november 2016
Záver
Význam každého archívu rastie s pribúdajúcim časom. Pri ojedinelých projektoch, akým projekt IS DIP je, si uvedomujeme, aká potrebná je spolupráca a výmena jedinečných skúseností. Naše poďakovanie preto patrí všetkým zúčastneným a zainteresovaným kolegom, osobitne z českého Webarchivu za ich cenné rady a skúsenosti.
Na základe uvedených skutočností a skúseností z realizácie projektu ako aj z komplexnosti riešenia možno konštatovať, že zber a archivácia digitálnych prameňov je komplexný a náročný proces. Prevádzka softvérových systémov, hardvéru i organizačno-metodické zabezpečenie rutinnej prevádzky IS DIP si vyžadujú nielen kontinuálnu údržbu, ale aj trvalo udržateľný rozvoj vrátane priebežnej inovácie pracovných metód a postupov. Veľa bude záležať aj od potrebnej zmeny legislatívneho rámca pre digitálne pramene a ich využívanie a v neposlednom rade aj od priebežného zabezpečenia finančných prostriedkov a ľudských zdrojov. Úlohou Univerzitnej knižnice v Bratislave je dlhodobo udržať IS DIP v prevádzke.
Digitálne technológie obohacujú informačné, publikačné a tvorivé procesy. Digitálne pramene – webové stránky a objekty a pôvodné elektronické publikácie a artefakty sú však v dlhodobom horizonte zo svojej podstaty ohrozené. Rýchlo a hromadne vznikajú, ešte rýchlejšie sa menia a zanikajú.
Ambíciou Univerzitnej knižnice v Bratislave je dlhodobo chrániť a uchovať toto svedectvo súčasnej epochy zabúdania. Veríme, že vďaka vzájomnému úsiliu a spolupráci s politikmi, autormi, kurátormi, redaktormi a tvorcami digitálneho obsahu sa nám to spoločne podarí!
Literatúra
MATÚŠKOVÁ, Jana, 2015. Politika zberu DIP www [online]. Dostupné na internete: https://www.webdepozit.sk/projekt-dip/dokumentacia/zoznam-dokumentov
KATRINCOVÁ, Beáta, 2015. Politika zberu DIP e-Born seriály [online]. Dostupné na internete: https://www.webdepozit.sk/projekt-dip/dokumentacia/zoznam-dokumentov.
ANDROVIČ, Alojz, Ivan CIGLAN a Jana MATÚŠKOVÁ. Digitálne pramene – webharvesting a archivácia e-Born obsahu. ITlib [online]. Centrum vedecko-technických informácií SR. 2016, č. 2. ISSN 1336-0779. Dostupné na internete: http://itlib.cvtisr.sk/buxus/docs/05_digitalne%20pramene..pdf.
Zákon č. 185/2015 Z. z. – Autorský zákon.
Zákon č. 212/1997 Z. z. o povinných výtlačkoch periodických publikácií, neperiodických publikácií a rozmnoženín audiovizuálnych diel v znení neskorších predpisov.